度小满在AI领域再创佳绩 两篇论文入选国际顶级会议
在多重因素的共同作用下,人工智能(AI)从单模态走向多模态发展已是大势所趋,而多模态、预训练排序也成为了当下乃至未来的研究热点。而作为AI领域资深玩家的度小满,也加快了对多模态、预训练排序等技术的研究步伐,并取得了不错的成绩。近期,度小满数据智能应用部AI-Lab围绕多模态、预训练排序撰写的两篇论文,就入选了国际顶级会议。
度小满数据智能应用部AI-Lab的两篇论文分别入选ACM MM和CIKM国际顶级会议。两篇论文分别就多模态和预训练排序等多个热门话题提出了新颖的算法,并在相关任务上达到了国际顶尖水平,获得了审稿人的一致好评并最终录用。这标志着度小满在自然语言处理和计算机视觉等人工智能前沿领域的研究得到了国际同行的认可。
度小满Transformer模型获国际顶级会议ACM MM认可
据悉,度小满具有实体对齐网格的位置增强Transformer被ACM MM录用(Position-Augmented Transformers with Entity-Aligned Mesh for TextVQA)。
许多图像除了实际的物体和背景等信息外,通常还包含着很有价值的文本信息,这对于理解图像场景是十分重要的。因此本论文主要研究基于文本的视觉问答任务,这项任务要求机器可以理解图像场景并阅读图像中的文本来回答相应的问题。然而之前的大多数工作往往需要设计复杂的图结构和利用人工指定的特征来构建图像中视觉实体和文本之间的位置关系。为了直观有效地解决这些问题,度小满科研人员提出了具有实体对齐网格的位置增强Transformer。
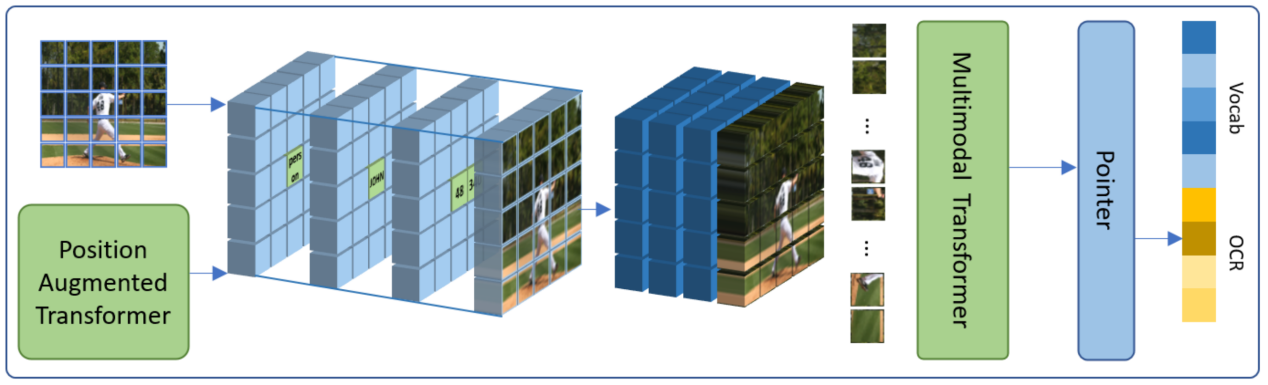
该模型能够整合目标检测、OCR以及基于Transformer的文本表示等多种方法的优势,增强算法对于图像中场景信息的理解,更精准的融合图像与文本多模态的信息,进一步助力证件识别、人脸与活体检测等业务场景,提升度小满在视觉风控方面的技术能力。
动态多粒度学习方法已在度小满多个业务场景广泛应用
另一篇基于BERT的动态多粒度排序模型则被CIKM录用(Dynamic Multi-Granularity Learning for BERT-Based Document Reranking)。
近年来,预训练的语言模型广泛应用于文本的检索排序任务中。然而,在真实场景中,用户的行为往往受到选择或曝光偏差的影响,这可能会导致错误的标签进而引入额外噪声。而对于不同候选文档,以往的训练优化目标通常使用单一粒度和静态权重。这使得排序模型的性能更容易受到上述问题的影响。因此,在该论文中度小满的科研人员重点研究了基于BERT的文档重排序任务,开创性地提出了动态多粒度学习方法。此外,该方法还同时考虑了文档粒度和实例粒度来平衡候选文档的相对关系和绝对分数。
该模型有效地提升了长文本理解与排序任务的性能,特别是其中所用到的预训练语言模型已经成为度小满在自然语言处理方面的基础架构,在获客、信贷等业务场景被广泛地使用,为业务模型提供了更加丰富的文本表示和精准的文本特征,在保障业务稳健发展中起到了十分重要的作用。
多模态、预训练排序能够在互联网发展过程中发挥重要作用,可以完成不同场景下的各种复杂任务。度小满专注于多模态和预训练排序的研究,并提出新颖算法,对业界研究多模态和预训练排序有着很好的引导作用。接下来,度小满将继续加强对创新技术的探索力度,更好巩固并发展自身的创新技术实力。

-
度小满在AI领域再创佳绩 两篇论文入选国际顶级会议
06-20 11:52
-
银行贷前调查:裁判文书、行政处罚、被执行人记录成为主要风险点
06-20 11:41
-
裁判文书、行政处罚、被执行人记录成为企业贷款的第二大障碍
06-20 11:40
-
云服务市场结构变革,华为云生态向ONE进化
06-20 11:09
-
以一持ONE:华为云抢跑生态之变
06-20 10:56
-
华为云的加速飞轮:助力伙伴修炼内功
06-20 10:55
-
40岁的薛凯琪保持少女感的秘诀…新西兰宝藏品牌soya garden
06-20 10:54
-
减龄教科书!我不允许还有人不知道这个宝藏护肤品牌soya garden
06-20 10:54
-
打通数字经济“大动脉”,联通云以原生价值赋能数字中国建设
06-20 10:43
-
中关村e谷产业星动派大咖云集,探讨商业航天的市场化破局
06-20 10:43
