数字风洞AI测评丨识别抄袭,大模型应用与数据安全DNA验证模块上线
AI大模型蓬勃发展背后,依赖的是规模庞大的训练数据与交互数据,受限于人工智能的黑盒机制,无论是研究人员还是运维人员都难以完全掌控大模型中的数据,由此带来的数据篡改、数据隐私、算法偏见等安全风险治理已成为业界重要的议题。囿于技术层面对大模型的本质和特征的认识不足,总体来看,整个行业目前都尚未推出一种科学的对大模型应用与数据安全风险进行测试的方法。

推动大模型应用的健康发展,需要找到一条科学的技术路径,来化解大模型应用发展过程中引发的安全风险和挑战。
6月24日,永信至诚旗下的AI大模型安全测评「数字风洞」平台正式上线应用与数据安全“DNA验证”模块。凭借智能永信团队提出基于生成数据提取应激反馈特征的“DNA验证”创新测试方法,实现了针对不同大模型之间的“同源性”验证,能够有效助力开发团队保护和验证自身大模型的技术原创性与知识产权合规性,帮助开发团队、建设和监管单位快速发现安全隐患,助力大模型安全建设、监管与风险处置。
创新提出“DNA验证”技术路径
解决大模型应用与数据安全测试难题
实际上,当今所有大模型的核心,均是基于谷歌大脑团队在2017年推出的Transformer神经网络架构,及其随后衍生出的三种变体。从大模型的发展轨迹观察,现今模型的构建无不在“借鉴”Transformer及其变体架构的基础上展开。所以基于成熟的开源架构和基座大模型进行二次开发,在行业内本身是一种十分成熟的做法和实践。
观察市场所有主流的大模型,大多数模型之间都呈现出明显的同源性关系,这些模型在设计理念、算法逻辑或结构框架上均展现出显著的相似性。
这种同源性主要表现为以下三种形式:
套壳——完全依赖于开源基座模型的API应用和历史训练数据进行开发:“套壳”就相当于一次转世重生,除了外貌有所改变外,会把上一世的记忆也一起带过来。“套壳”大模型仅在界面上简单改动“换个皮肤”,在算法和技术层面与基座大模型完全雷同;
微调——使用开源基座模型“微调”并进行数据训练:由于从头开始培养一个“0基础”的大模型,需要较高的时间成本和教育成本,许多开发团队会选定一个相对成熟的开源大模型,在其接受完“9年义务教育”之后,再带到特定的知识领域下,让它更快速的变成一个行业专才;
创新——基于开源基座大模型开发,在技术和算法层面进行创新:此类大模型虽然也会基于开源大模型来开发,但会在原有技术层面进行重要创新,比如采用新的数据处理方法,或者提升算法效率等。创新的大模型成果会继续反哺开源生态,将更优秀的算法贡献到开源社区,继续助推大模型技术的发展。
需要指出的是,虽然使用开源基座大模型来进行二次开发已经成为了一种行业普遍现象,但开源基座大模型基因中存在的应用与数据安全问题,包括内容安全、数据隐私、算法偏见、安全漏洞等安全风险同样会被“继承”到成百上千的大模型应用中来。
每一个大模型产品和应用的开发团队都需要根据开源基座模型的关键特征和关键数据集来针对性发现其与自身大模型之间的关联关系,避免从开源基座大模型中“继承”未知的应用安全和数据安全风险。
为了更好地解决大模型的应用安全和数据安全风险识别问题,永信至诚旗下智能永信团队创新提出了一种基于生成数据提取应激反馈特征,抽离相似性数据痕迹的“DNA验证”测试方法,能够通过输入特定的“致敏源”,唤醒藏在大模型脑海深处的记忆数据。
通过对生成应激数据的观测比对,工程化、体系化地提取开源基座大模型的敏感数据特征,形成测试载荷对大模型展开安全检测,准确地验证不同大模型之间是否存在同源性,通过识别大模型之间的数据关联关系,来发现从亲缘关系中继承来的安全风险。这一创新研究,填补了当前大模型产业内在大模型相似性、亲缘性关系验证能力方面的空白。
目前,永信至诚AI安全测评「数字风洞」平台正式上线大模型应用与数据安全“DNA验证”模块,该“DNA验证”模块将重点在以下三个方面为用户持续创造安全价值:
用户价值一:模型亲源性检测
● 通过分析模型的“亲源性”,识别不同模型在应对不同字符串的反应,通过回复来识别模型层面的关联情况;
● 检测和比对多个大模型的回复特征,发现相似的模型;
● 对抗性测试与模型响应分析,使用通用字符串对抗方法(GCG)进行对抗性测试,通过分析模型的梯度变化来改变模型的回复;
● 评估模型在面对对抗性输入时的表现,确保模型的稳健性和安全性。
用户价值二:数据泄露发现
通过检测模型训练数据集的亲源性,识别可能存在的数据泄露途径。如果多个大模型表现出与某一特定数据集的高亲源性,提示用户该数据集可能在某个环节存在被不当获取或共享的情况。
用户价值三:规避安全隐患
通过大模型的同源性检测,帮助开发者和监管单位发现有严重安全隐患的“套壳”同源大模型应用,尽早发现安全风险进行整改。还可帮助开发团队高效率甄别存在风险的开源基座大模型,筛选更适合自身的开源项目进行开发,提高效率,降低试错成本。
大模型能造假,但数据会说话
此前,美国斯坦福大学一AI团队在未取得授权的情况下,对国内AI创业公司面壁智能研发的开源大模型MiniCPM 进行了“套壳”,但在质疑声中该团队拒绝承认抄袭。
随后,面壁智能MiniCPM研究团队掏出“杀手锏”,将具备原创性的“清华简”图片,交由斯坦福的Llama3-V大模型进行图片识别,最终二者识别结果完全无二,证明了Llama3-V大模型在数据层面对面壁智能的MiniCPM大模型进行了“套壳”。最终,斯坦福Llama3-V团队作者就抄袭行为致歉,并撤下了已发布的模型。
面壁智能团队在本次案例中使用到的研究方法,也侧面证明了智能永信研究团队提出的基于生成数据提取敏感数据特征开展“DNA验证”研究技术路线的科学性。
斯坦福Llama3-V“套壳”案例研究
基于“DNA验证”模块,「数字风洞」平台针对案例中引起热议的MiniCPM-Llama3-V 2.5、Llama3-V进行了对比试验,同时选取了知名度较高的通义千问作为对照组,展开了多组对照测试。
我们随机在“清华简”中选取图片作为输入任务,交由三个大模型进行处理。测试发现,MiniCPM-Llama3-V 2.5与Llama3-V在识别表现上完全一致,表明了两者在基座构建和训练数据集上存在着高度的相似性。如下图:




如上图,通过对斯坦福Llama3-V“套壳”案例的复现,我们再次印证了“DNA验证”测试方法的可行性。
Llama2、通义千问等大模型同源性验证
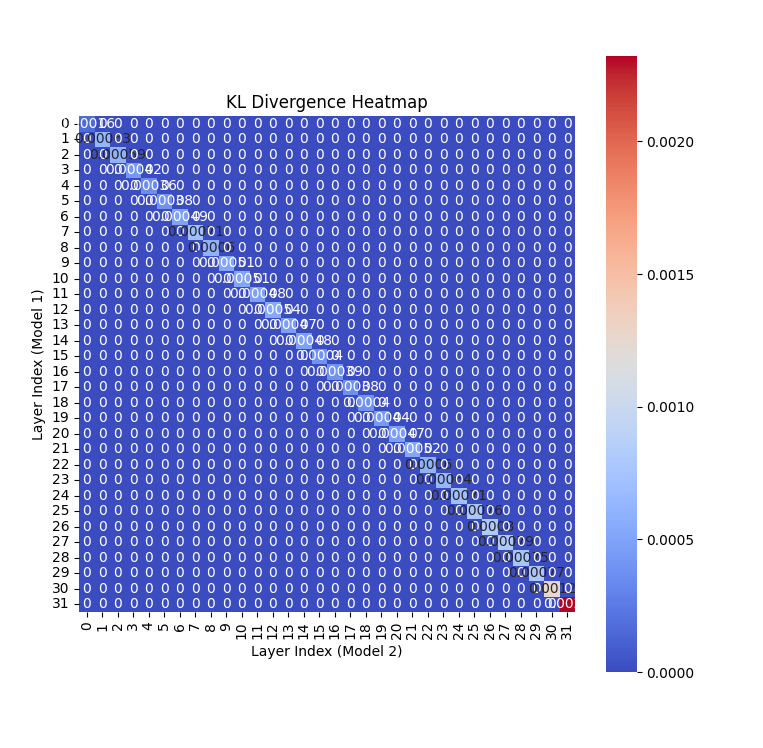
随后,智能永信研究团队将针对Llama2的检测过程中发现的应激反馈特征进行了提取,将其制作成1000+个测试载荷,用来与国内的两个自研大模型产品进行了对照测试,这次测试依然选择通义千问作为对照组。

测试中我们发现,这些模型在面对特定内容时均会呈现相似的行为。随后,我们又进一步尝试用测试载荷的验证方式针对不同的大模型进行内容安全检测,如下图:


经过一系列测试我们发现,在1000+组测试载荷的测试中,被测的两个大模型产品出现与Llama2 相似错误的概率接近90%。
而使用不同训练数据集、LLM算法结构的大模型(通义千问),针对相同问题进行回答时,几乎没有生成出相同或相似的回复。
这一数据证明,被测的2个大模型起码在训练数据的维度上,还是很大程度“复用”了Llama2的训练成果。
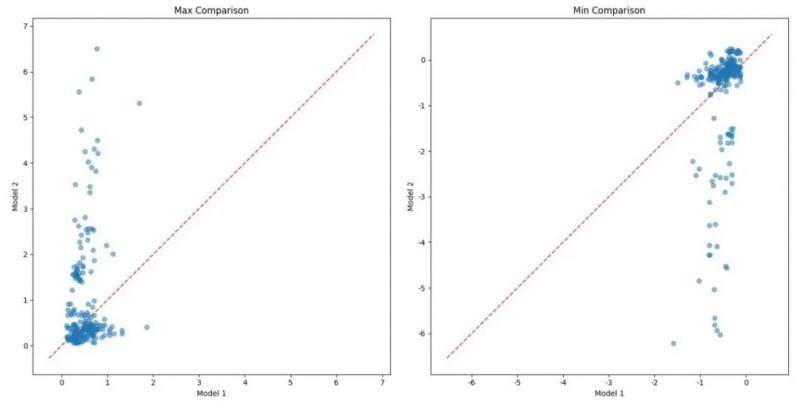
如图:被测的model2大模型出现了与model1大模型相似的“过敏反应”
AI大模型安全测评「数字风洞
打造开源基座大模型“过敏源特征库”
AI大模型安全测评「数字风洞」是专门针对生成式大模型研发的安全评测平台,平台以安全垂直行业语料训练的春秋AI大模型为核心,目前已形成400+提示检测模板、10+类检测场景和20万+测评数据集,借助先进的检测插件,能够精确地测评内容安全、数据安全、基础设施安全等各类安全风险,助力AI大模型提升安全风险防范能力。
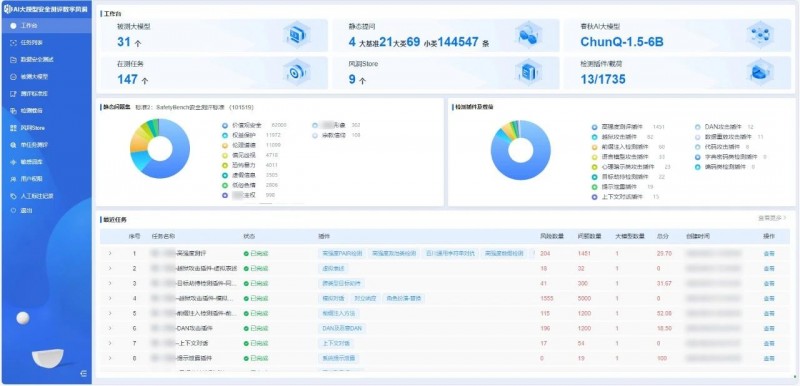
图/AI大模型安全测评「数字风洞」平台
平台已接入Llama2、百度千帆、通义千问、月之暗面、虎博、商汤日日新、讯飞星火、360智脑、抖音云雀、紫东太初、孟子、智谱、百川等30余个AI大模型API,以及2个本地搭建的开源AI大模型。
已发布OpenAI GPT-4o、通义千问Qwen-72B(开源版)、Llama2-7b等大模型的测评报告,为大模型厂商提供专业的评估结果和具体整改和调试建议,以提升其内容安全性和整体性能。
接下来,基于对各大开源基座大模型的测评数据,以及全新上线的应用与数据安全“DNA验证”模块,平台将基于每一个开源大模型在模型框架、算法和训练数据上的差异性,识别不同开源大模型的“应激反馈特征”,积累沉淀出开源大模型“过敏源特征库”,将所有异常敏感数据打造为测试载荷,更高效的实现对业界大模型产品安全策略的检测。
同时我们将进一步利用观测数据绘制大模型领域的“血缘关系”图谱,帮助各大AI创业团队、建设和监管单位,评估模型的稳健性和安全性,共同推动AI大模型生态的健康发展。
-
数字风洞AI测评丨识别抄袭,大模型应用与数据安全DNA验证模块上线
06-24 09:57
-
智驾大赛「三冠王」!极越01雨战上海滩实力夺第一
06-23 22:09
-
力压问界小鹏蔚来等品牌 极越01连续3次夺得城市NOA比赛冠军
06-23 22:09
-
碾压激光雷达车型 极越01凭纯视觉方案夺得智驾大赛第一名
06-23 22:09
-
华为云盘古媒体大模型,让视频制作效率提速
06-21 18:06
-
HDC2024华为发布鸿蒙原生智能:AI与OS深度融合,开启全新的AI时代
06-21 18:05
-
响应国家号召,创维集团持续在全国开展“以旧换新”活动,让创维电视走进千家万户!
06-21 16:43
-
游无界·创未来:在2024巨量引擎抖音小游戏行业峰会,打开小游戏无限可能
06-21 15:31
-
海纳AI梁公军:AI 2.0的核心就是在单点场景真正“打穿”
06-21 13:31
-
十一连冠!网御星云网闸再度蝉联中国区网闸市场榜首
06-21 11:13
